链表(Linked list) 是一种 动态 的线性数据结构,但并不是按线性的顺序存储数据。链表通常由一连串结点(Node)组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向上一个/或下一个节点的位置的引用(prev或next)。
链表的优点是不需要处理固定容量的问题,但是链表失去了数组随机读取的优点。
1. 链表
链表是一种天然带有递归性质的线性结构,在链表中数据存储在结点中,结点中同时存储了指向下一个结点的引用(这里只介绍单向链表)。
链表类中的操作:
| 方法 |
描述 |
| int getSize() |
获取链表中元素个数 |
| boolean isEmpty() |
返回链表是否为空 |
| void add(int index, E e) |
在链表的 index 位置添加新元素 e |
| void addFirst(E e) |
在链表头部添加新元素 e |
| addLast(E e) |
在链表末尾添加新元素 e |
| E get(int index) |
获得链表的第 index 个位置的元素 |
| E getFirst() |
获得链表的第一个元素 |
| E getLast() |
获得链表的最后一个元素 |
| E set(int index, E e) |
修改链表的第 index 个位置的元素为 e,返回该位置之前的元素 |
| boolean contains(E e) |
查找链表中是否存在元素 e |
| E remove(int index) |
从链表中删除第 index 个位置的元素,返回被删除的元素 |
| E removeFirst() |
从链表中删除第一个元素,返回被删除的元素 |
| E removeLast() |
从链表中删除最后一个元素,返回被删除的元素 |
| void removeElement(E e) |
从链表中删除元素e |
1
2
3
4
5
|
class Node {
E e;
Node next;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| public class LinkedList<E> {
private class Node {
public E e;
public Node next;
public Node(E e, Node next) {
this.e = e;
this.next = next;
}
public Node(E e) {
this(e, null);
}
public Node() {
this(null, null);
}
@Override
public String toString() {
return e.toString();
}
}
}
|
2. 向链表中添加元素
| 方法 |
描述 |
| int getSize() |
获取链表中元素个数 |
| boolean isEmpty() |
返回链表是否为空 |
| void add(int index, E e) |
在链表的 index 位置添加新元素 e |
| void addFirst(E e) |
在链表头部添加新元素 e |
| addLast(E e) |
在链表末尾添加新元素 e |
先将链表类的几个基本属性和方法声明出来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| public class LinkedList<E> {
private class Node{
public E e;
public Node next;
public Node(E e, Node next){
this.e = e;
this.next = next;
}
public Node(E e){
this(e, null);
}
public Node(){
this(null, null);
}
@Override
public String toString(){
return e.toString();
}
}
private Node head;
private int size;
public LinkedList(){
head = null;
size = 0;
}
public int getSize(){
return size;
}
public boolean isEmpty(){
return size == 0;
}
}
|
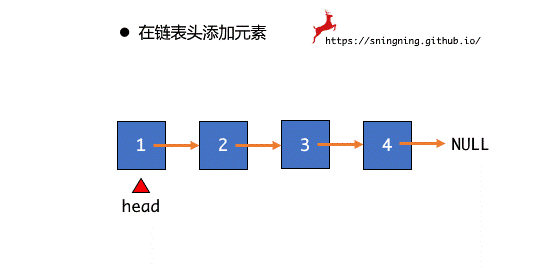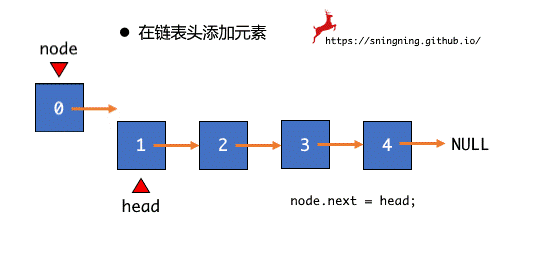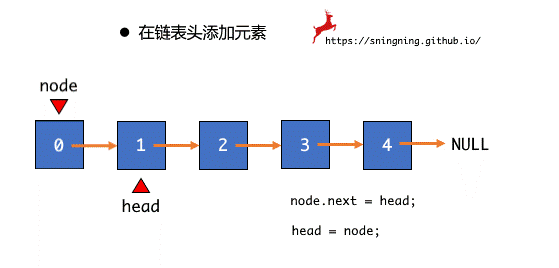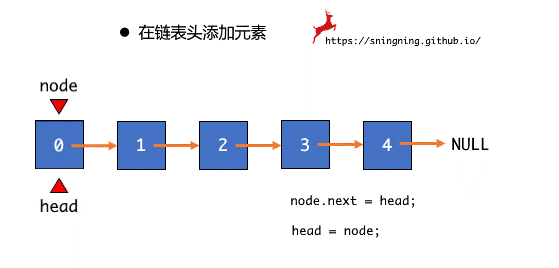
在链表头部添加元素,只需将之前整个链表的 head 赋给新插入结点的 next ,同时维护 head 和 size。
1
2
3
4
5
6
|
public void addFirst(E e) {
head = new Node(e, head);
size ++;
}
|
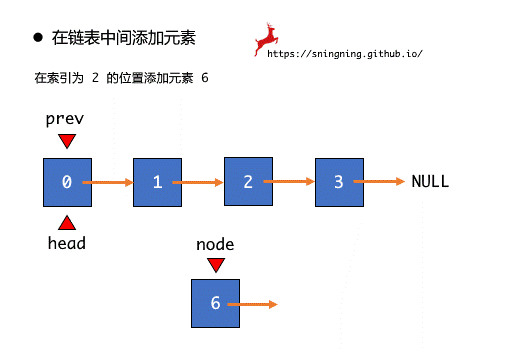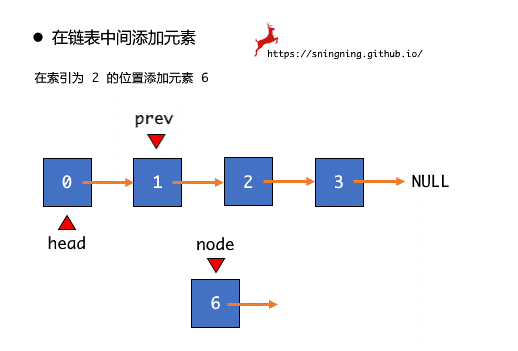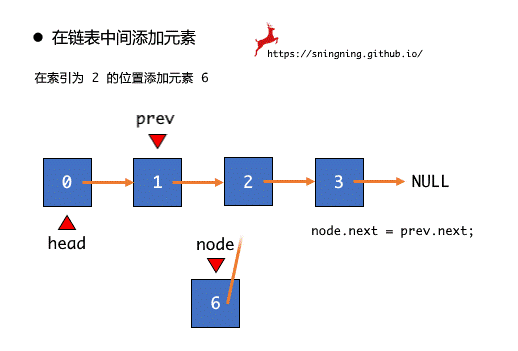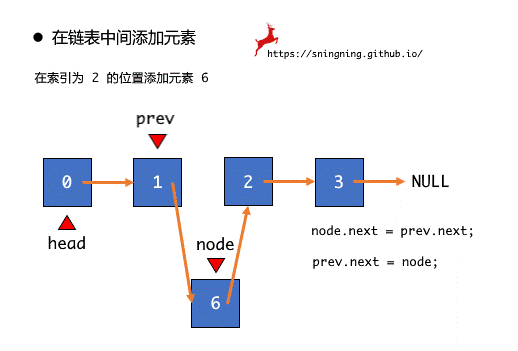
根据图示可以看出,在某个位置添加元素最重要的是要找到前一个结点,设置一个结点引用 prev,通过移动 prev 找到待插入的位置的前一个位置,之后进行 node.next = prev.next 和 prev.next = node 两步操作就可以完成在某个位置添加元素的操作,最后维护 size。注意此时 prev 移动的次数,如果放在 3 这个位置,那么 prev 移动 2 次,即当 prev == 2 时就停止,所以循环条件是 i < index - 1。
但是,如果 index == 0,即在链表头添加元素,由于 head 没有前一个结点,所以这种情况下需要单独处理。
切记两个操作不开颠倒顺序,否则,当执行完 prev.next = node 时,prev.next 已经指向了 node,再执行 node.next = prev.next 就出现了逻辑上的错误。
需要说明的是,在链表中一个位置添加元素是不常用的操作,其实在链表中没有索引这个概念,这里只是借助这个概念。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
public void add(int index, E e) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("添加失败,索引非法。");
}
if (index == 0) {
addFirst(e);
}
else {
Node prev = head;
for (int i = 0; i < index - 1, i++) {
prev = prev.next;
}
prev.next = node(e, prev.next);
size++;
}
}
|
在链表末尾添加元素就可以直接复用 add(int index, E e) 方法,将 index 设置为 size 即可。
1
2
3
4
|
public void addLast(E e){
add(size, e);
}
|
3. 虚拟头结点
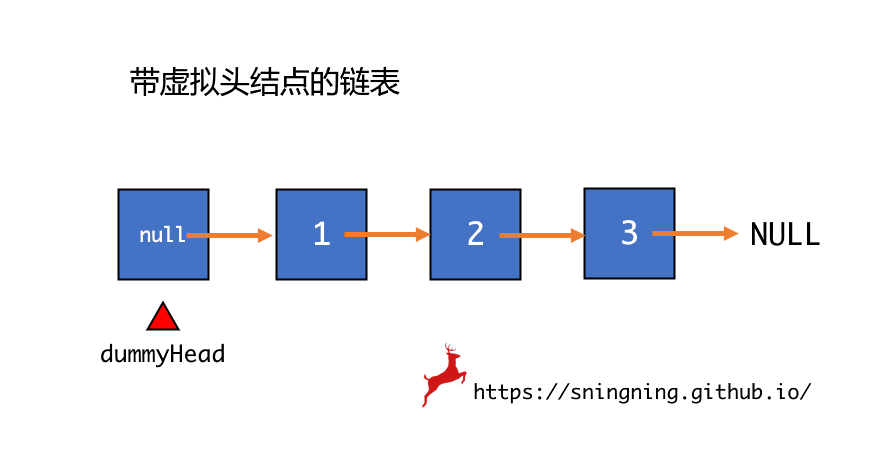
之前在向链表中添加元素时,如果是在头部添加元素,由于头结点没有前结点,因此需要单独考虑。为了将对链表头的操作与其他操作统一起来,设立一个虚拟头结点(dummyHead),虚拟头结点不存储元素,只有一个指向 head 的引用。
有了虚拟头结点,便可以将添加操作统一起来。新增 dummyHead 属性,初始化时将其建立起来,但元素值和 next 引用均为空。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| public class LinkedList<E> {
private class Node{
public E e;
public Node next;
public Node(E e, Node next) {
this.e = e;
this.next = next;
}
public Node(E e) {
this(e,null);
}
public Node() {
this(null,null);
}
@Override
public String toString() {
return e.toString();
}
}
private Node dummyHead;
private int size;
public LinkedList(){
dummyHead = new Node(null, null);
size = 0;
}
public int getSize() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
}
|
有了虚拟头结点后,从链表头部添加元素就不需要再单独考虑,因为 dummyHead 中 next 就指向链表第一个元素。注意,增加了虚拟头结点后,只需遍历 index 次,所以循环继续进行的条件是 i < index。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public void add(int index, E e) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("添加失败,索引非法。");
}
Node prev = dummyHead;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
prev.next = new Node(e, prev.next);
size ++;
}
|
此时向链表头部添加元素就可以复用 add 方法。
1
2
3
4
|
public void addFirst(E e) {
add(0, e);
}
|
4. 链表的遍历、查询和修改
| 方法 |
描述 |
| E get(int index) |
获得链表的第 index 个位置的元素 |
| E getFirst() |
获得链表的第一个元素 |
| E getLast() |
获得链表的最后一个元素 |
| E set(int index, E e) |
修改链表的第 index 个位置的元素为 e,返回该位置之前的元素 |
| boolean contains(E e) |
查找链表中是否存在元素 e |
在链表中是不常使用索引的,因此 get 方法也不经常使用,更多是用来熟悉链表的遍历操作。
查询操作是需要找到 index 位置的结点,而添加操作是要找到 index 的前一个结点,因此对于查询操作,从链表真正的第一个结点开始遍历,由于设置了虚拟头结点,因此,遍历操作是从 dummyHead.next 进行的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public E get(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("获取失败,索引非法。");
}
Node cur = dummyHead.next;
for (int i = 0; i < index; i++) {
cur= cur.next;
}
return cur.e;
}
|
获取链表中第一个元素和最后一个元素就可以直接复用 get 方法。
1
2
3
4
|
public E getFirst() {
return get(0);
}
|
1
2
3
4
|
public E getLast() {
return get(size - 1);
}
|
同样,修改元素也和查询元素一样需要遍历,只不过是把 index 位置的结点中数据域进行修改,最后维护 size。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public E set(int index, E e) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("获取失败,索引非法。");
}
Node cur = dummyHead.next;
for (int i = 0; i < index; i++>) {
cur = cur.next;
}
E t = cur.e;
cur.e = e;
size--;
return t;
}
|
设置一个查找的方法 contains(E e),查询链表中是否包含元素 e。由于此时不知道具体索引位置,因此需要遍历整个链表,需要不断进行,直到到达链表的最后。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public boolean contains(E e) {
Node cur = dummyHead.next;
while (cur != null) {
if (cur.e.equals(e)) {
return true;
}
cur = cur.next;
}
return false;
}
|
为了方便输出,重写 toString() 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
| @override
public void toString() {
StringBuilder res = new StringBuilder();
for (Node cur = dummyHead.next; cur != null; cur = cur.next) {
res.append(cur + "->");
}
res.append("NULL");
return res.toString();
}
|
5. 从链表中删除元素
| 方法 |
描述 |
| E remove(int index) |
从链表中删除第 index 个位置的元素,返回被删除的元素 |
| E removeFirst() |
从链表中删除第一个元素,返回被删除的元素 |
| E removeLast() |
从链表中删除最后一个元素,返回被删除的元素 |
| void removeElement(E e) |
从链表中删除元素e |
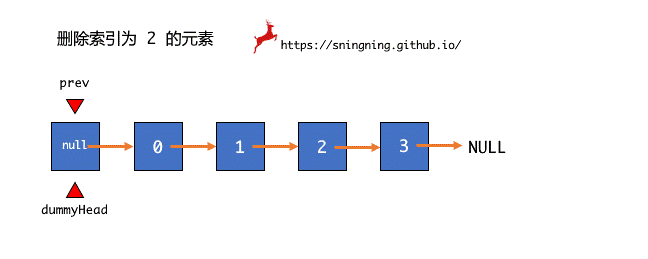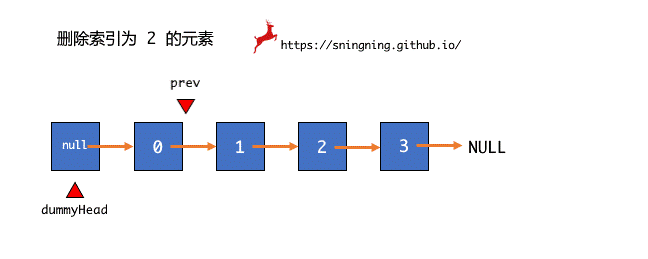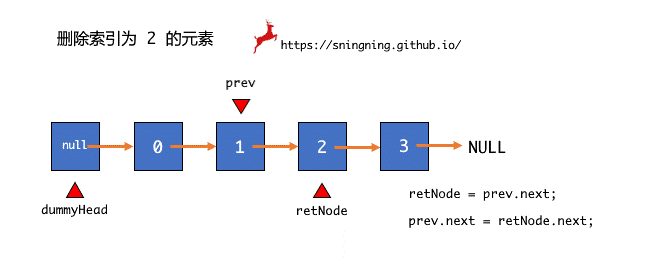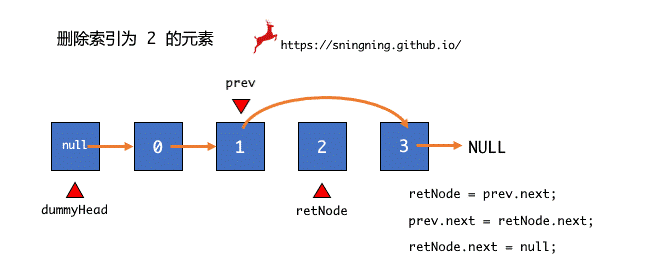
想要实现在链表 index 位置删除元素,和添加元素一样,先找到待删除元素的前一个结点 prev,然后将待删除结点用临时结点 retNode 暂存起来,然后跳过待删除结点,直接将待删除结点的下一个结点赋给 prev 的 next 引用。为了避免对象游离,将待删除结点 retNode 的 next 引用设置为空。最后将 retNode 结点的数据返回并维护 size。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
public E remove(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("删除失败,索引非法。");
}
Node prev = dummyHead;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
Node retNode = prev.next;
prev.next = retNode.next;
retNode.next = null;
size--;
return retNode.e;
}
|
有了 remove 方法,从链表中删除第一个元素和最后一个元素就可以直接复用 remove 方法。
1
2
3
4
|
public E removeFirst() {
return remove(0);
}
|
1
2
3
4
|
public E removeLast() {
return remove(size - 1);
}
|
要想从链表中删除元素,最重要的是要先找到它,找到之后,就和删除某个位置的元素一样操作就可以了。寻找的过程还是链表遍历的过程,删除元素是要找到待删除元素之前的结点 prev,因此遍历链表时从 dummyHead 开始,同时,遍历结束的条件是 prev.next == null。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public void removeElemet(E e) {
Node prev = dummyHead;
while (prev.next != null) {
if (prev.next.e.equals(e)) {
break;
}
prev = prev.next;
}
if (prev.next != null) {
Node retNode = prev.next;
prev.next = retNode.next;
retNode.next = null;
size--;
}
}
|
6. 链表操作的时间复杂度
添加操作
| 方法 |
时间复杂度 |
| add(int index, E e) |
O(n/2) = O(n) |
| addFirst(E e) |
O(1) |
| addLast(E e) |
O(n) |
由于在末尾添加元素需要遍历整个链表,所以时间复杂度为 O(n);而在链表头部添加元素,是 O(1) 的时间复杂度;以上两个操作的时间复杂度是和数组相反的。当在链表任一位置插入元素是,平均来看,是往链表的中间添加元素,时间复杂度为 O(n/2),总体也是 O(n) 级别。
删除操作
| 方法 |
时间复杂度 |
| remove(int index) |
O(n/2) = O(n) |
| removeFirst() |
O(1) |
| removeLast() |
O(n) |
| removeElement(E e) |
O(n/2) = O(n) |
如果删除最后一个元素,需要从头遍历整个链表,时间复杂度为 O(n);删除第一个元素,只需 O(1) 的时间复杂度;这两个操作的时间复杂度和数组也是相反的。平均来看,remove(int index) 和 removeElement(E e) 的时间复杂度为 O(n)。
修改、查找操作
| 方法 |
时间复杂度 |
| set(int index, E e) |
O(n) |
| get(int index) |
O(n) |
| getFirst() |
O(1) |
| getLast() |
O(n) |
| contains(E e) |
O(n) |
链表的修改和查找操作时间复杂度也是 O(n)。
总的来说,如果只对链表的头部进行操作,或者只对链表头部进行查找,时间复杂度是 O(1),
链表整体实现: LikedList.java
7. 使用链表实现栈
栈的接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public interface Stack<E> {
int getSize();
boolean isEmpty();
void push(E e);
E pop();
E peek();
}
|
由于在链表头操作的时间复杂度为 O(1),因此栈的 pop 和 push 都应在链表头进行,也就是说,链表的头部是栈顶,尾部是栈底。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
public class LinkedListStack<E> implements Stack<E> {
private LinkedList<E> linkedList;
public LinkedListStack() {
this.linkedList = new LinkedList<>();
}
@Override
public int getSize() {
return linkedList.getSize();
}
@Override
public boolean isEmpty() {
return linkedList.isEmpty();
}
@Override
public void push(E e) {
linkedList.addFirst(e);
}
@Override
public E pop() {
return linkedList.removeFirst();
}
@Override
public E peek() {
return linkedList.getFirst();
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append("Stack: ");
res.append("top [");
res.append(linkedList);
res.append("]");
return res.toString();
}
}
|
8. 使用链表实现队列
对于队列,要在一端添加元素,另一端删除元素,但是对于链表来说势必会有一个 O(n) 的操作,其实之前用数组实现队列的时候也有同样的问题,不过用循环队列改进后,性能就提升了。因此用链表实现队列,也进行改进。
由于有 head 变量,所以之前对于链表头部的操作都是简单的,因此,可以考虑同时在链表尾部设置 tail 变量,指向最后一个结点,在对链表操作的时候,同时维护 tail。
添加了 tail 之后,想要在尾部添加元素就变得很方便,相当于在 tail 后面添加一个结点,这是,从链表的头部和尾部添加元素都是容易的
添加了 tail 之后,要想在尾部删除元素,就是说要找到 tail 前一个结点,但找到前一个结点又要进行遍历,所以从尾部删除元素是不容易的。
总的来说,添加 tail 变量之后,在链表尾部添加元素变得方便,而在头部添加或删除都是方便的,因此,选择在链表头部删除元素,在链表尾部添加元素,即:将链表头作为队首,链表尾部作为队尾。
先将简单的操作进行实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| public class LinkedListQueue<E> implements Queue<E> {
private class Node {
public E e;
public Node next;
public Node(E e, Node next) {
this.e = e;
this.next = next;
}
public Node(E e) {
this(e,null);
}
public Node() {
this(null,null);
}
@Override
public String toString() {
return e.toString();
}
}
private Node head, tail;
private int size;
public LinkedListQueue() {
this.head = null;
this.tail = null;
this.size = 0;
}
@Override
public int getSize() {
return this.size;
}
@Override
public boolean isEmpty() {
return size == 0;
}
}
|
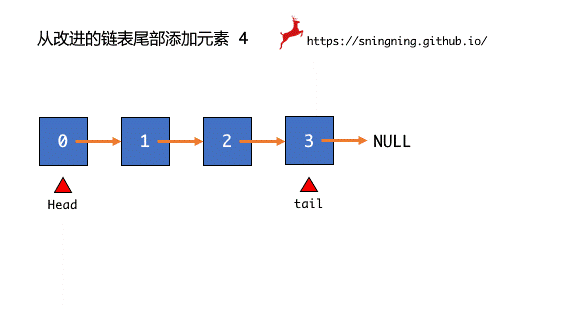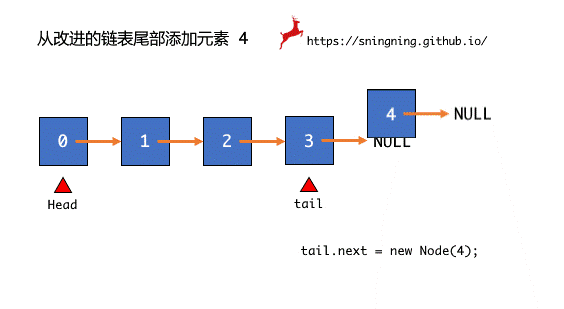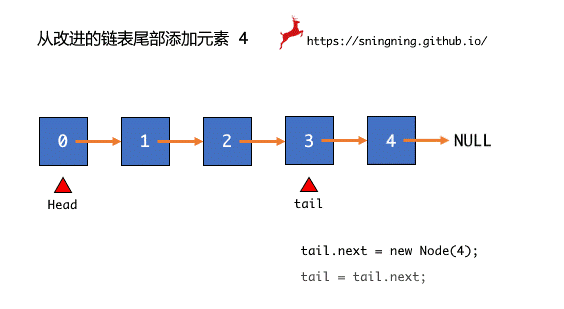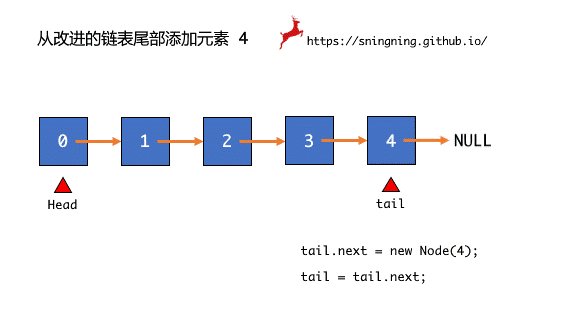
进行入队操作,如果队列不为空,则直接将元素添加到最后即可,同时维护 tail 和 size。当队列为空时,head 和 tail 均指向 null,此时向空队中添加一个元素时,直接将 tail 指向入队的那个结点,同时维护 head 和 size。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Override
public void enqueue(E e) {
if (tail == null) {
tail = new Node(e);
head = tail;
}
else {
tail.next = new Node(e);
tail = tail.next;
}
size ++;
}
|
正常出队的时候,只需按照链表中删除第一个元素,维护 size 即可。但是要注意,当队列中只有一个元素,head.next 为空,经过 head = head.next 操作后,队列已经为空,此时 head == null,因此还需要额外维护下 tail。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| @Override
public E dequeue() {
if (isEmpty()) {
throw new IllegalArgumentException("队列为空。");
}
Node retNode = head;
head = head.next;
retNode.next = null;
if (head == null) {
tail = null;
}
size --;
return retNode.e;
}
|
查看队首元素只需将 head 数据域中的元素返回即可。
1
2
3
4
5
6
7
8
9
| @Override
public E getFront() {
if (isEmpty()) {
throw new IllegalArgumentException("队列为空。");
}
return head.e;
}
|
最后重写 toString() 方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append("Queue: front ");
Node cur = head;
while (cur != null) {
res.append(cur + "->");
cur = cur.next;
}
res.append("NULL tail");
return res.toString();
}
|
用链表实现栈整体实现:LinkedListQueue.java
参考资料